An observation about organization - so many things are distributed, in the spirit of Hadoop distributed nature. Examples - one big hall for lunch and presenters' booths is in one end of the building, the sessions are in the other end of the building - so people have to walk there and back. Another example - lunch: boxes with sandwiches on one side of the hall, soda is on the other...
There are no power sockets to plug your laptop. Only a couple of them along the walls.
Several sessions are over-capacitated. Couldn't get to some of the sessions.
But anyway here are some session notes:
Hadoop sessions notes
== AWS (Amazon Web Services) big data infrastructure
- Netflix streams data from S3 directly into MapReduce (w/o HDFS) and back
- Netflix bumps up from 300 to 400+ nodes over weekend
- Netflix has an additional query cluster
- Cheaper Experimentation = Faster Innovation
- Logs are stored as JSON in S3
- Honu a tool that aggregates logs and makes it available as Hive tables for analysts https://github.com/jboulon/Honu
Another climate prediction company:
- Provision a cluster, send data, run jobs, shut down the cluster.
Case study airbnb (find a place to stay) - they moved from RDS to DinamoDB (Amazon nosql db)
and use S3 for data storage
== Unified Big Data Architecture: Integrating Hadoop within an Enterprise Analytical Ecosystem - Aster
Different data:
- stable schema (structured) - data from RDB's, ... Use Teradata or Hadoop sometimes
- evolving schema (semi-structured) - web logs, twitter stream, ... Hadoop, Aster for joining with structured data and for SQL+MapReduce
- no schema (unstructured), PDF files, images,... Hadoop, sometimes Aster for MapReduce Analytics

Aster SQL-H - for business people
- ANSI SQL on Hadoop data
- through HCatalog it connects to Hive and HDFS

== Scalding (new Hadoop language from Twitter)
- it looked to me as a library for Scala and Cascading
- it can read/write from/to HDFS, DBs, MemCache, etc...
- the model is similar to Pig and coding style is similar to Cascading
- you can develop locally without shipping to hadoop
- I was loosing track actually when the guy was talking about scala or cascading or scalding because of lack of my knowledge in these things
- scala is a language for writing, not reading (personal impression)
== Microsoft Big Data
- Microsoft wants to make sure that Hadoop works well on Azur as well as Windows
- On Azur it has neat UI for administration and data processing
- It has Hive console to create and manage Hive tables
- It's all on http://hadooponazure.com
- Integrating Excel to hadooponazure. You download an odbc driver for Hive and connect your Excel to Hive data.
- Then can you can build Hive data and pull data to excel. Then this excel doc is uploaded to SharePoint where do all sorts of reporting, pivoting and charting. Once you republish this document to the SharePoint then you can schedule this excel document to refresh itself from hadoop with a certain cadency.
.NET also has a neat way to programmatically submit the Hive jobs.
JavaScript can call Hadoop jobs from "Interactive JavaScript console" in hadooponazure.com. You can query hive and parse the results into json and then graph it.
Hadoop you do? I am fine... -- funny sentence.
Overall: Microsoft did a good job in bringing Hadoop to the less technically prepared people.
== Hadoop and Cloud @ Netflix
- They recommend movies based on Facebook (user's profile, friends)
- Everything is personalized
- 25M+ subscribers
- 4M/day ratings
- Searches: 3M/day
- Plays: 30M/day
They use
- Hadoop
- Hive
- Pig
- Java
They use "Markov Chains" algorithm.

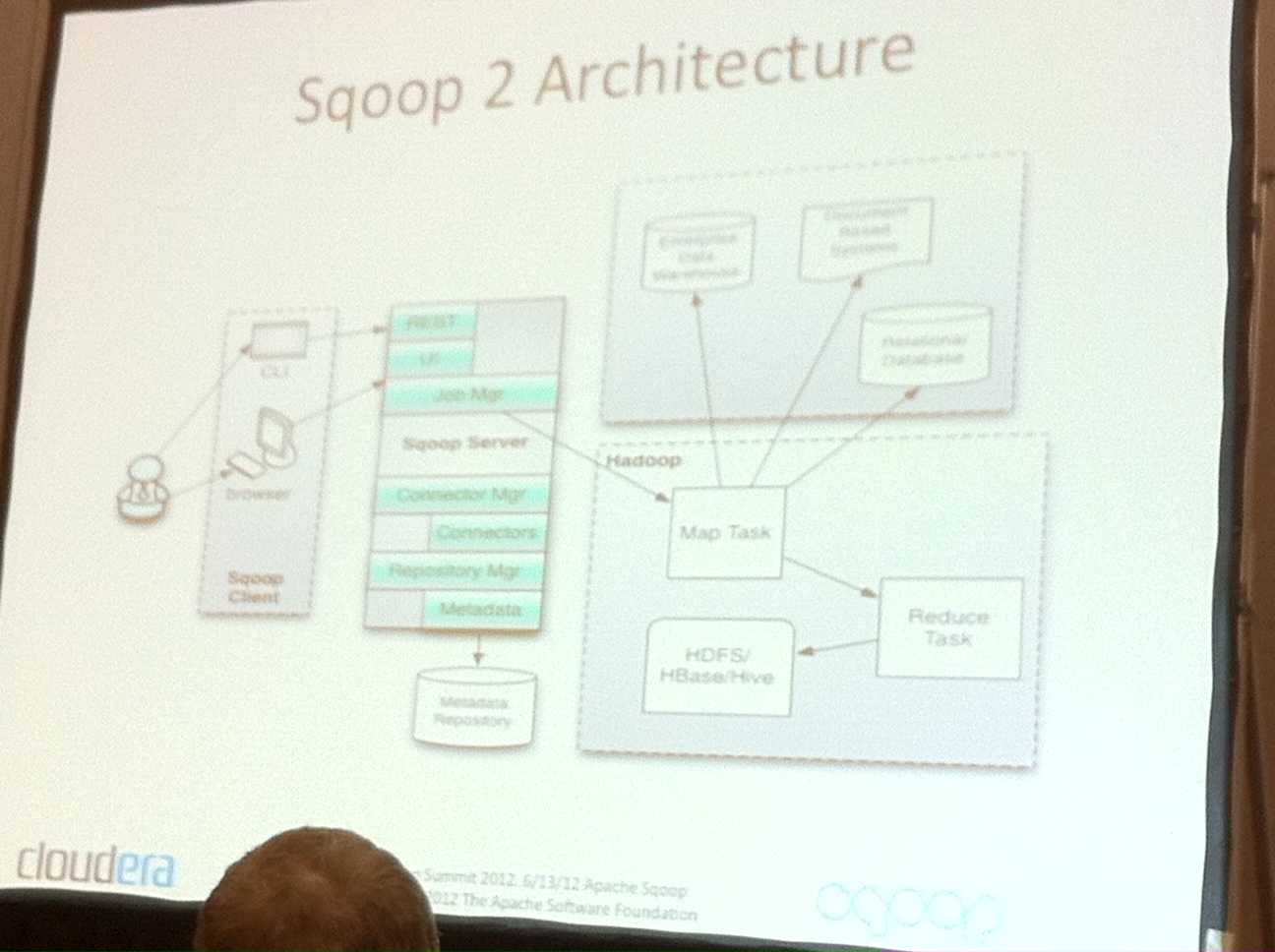
Sqoop 2
- It's moving data from/to relational and non-relational databases
- It's much easier to use than sqoop 1
- It has UI admin panel
- It's now client-server as opposed to only client sqoop 1
- It's easier to integrate with Hive and HBase. In fact you can not only move data from db's to hdfs but also further move data to hive tables or hbase tables
- It is going to be more secure
No comments:
Post a Comment